2026-06-23 · 7 min · llm · glm · long-context · agentic-coding · explainer
GLM 5.2, from Z.ai (Zhipu AI), is the flagship of the GLM-5 line: a 744-billion- parameter mixture-of-experts with 40B active per token, MIT-licensed open weights, and — the headline — a genuine 1-million-token context. It is tuned for one thing in particular: long-horizon agentic coding, the sessions that run hundreds of rounds and thousands of tool calls without losing the thread.
There is no standalone GLM 5.2 paper. It builds on the GLM-5 technical report (arXiv 2602.15763) and, for the context trick at its center, a method paper — IndexCache / IndexShare (arXiv 2603.12201). This pulls from both, plus the release blog.
What changed from 5.1
GLM-5 → 5.1 → 5.2 share the same 744B/40B backbone. What 5.2 adds:
- a real 1M-token context, up from 200K;
- IndexShare, the architecture change that makes that context affordable;
- a shift to critic-based PPO for very long RL rollouts;
- faster speculative decoding (+20% acceptance length);
- a thinking-effort dial (High / Max).
The first two are the load-bearing pair: the long context, and the trick that keeps it cheap.
The model
744B total parameters, 40B active per token — a mixture-of-experts on an 80-layer, 256-expert backbone. Attention is DeepSeek Sparse Attention (DSA): Multi-head Latent Attention plus a lightweight indexer that, for each query, selects the top- tokens worth attending to instead of the whole sequence. That sparsity is what makes a million-token context tractable at all.
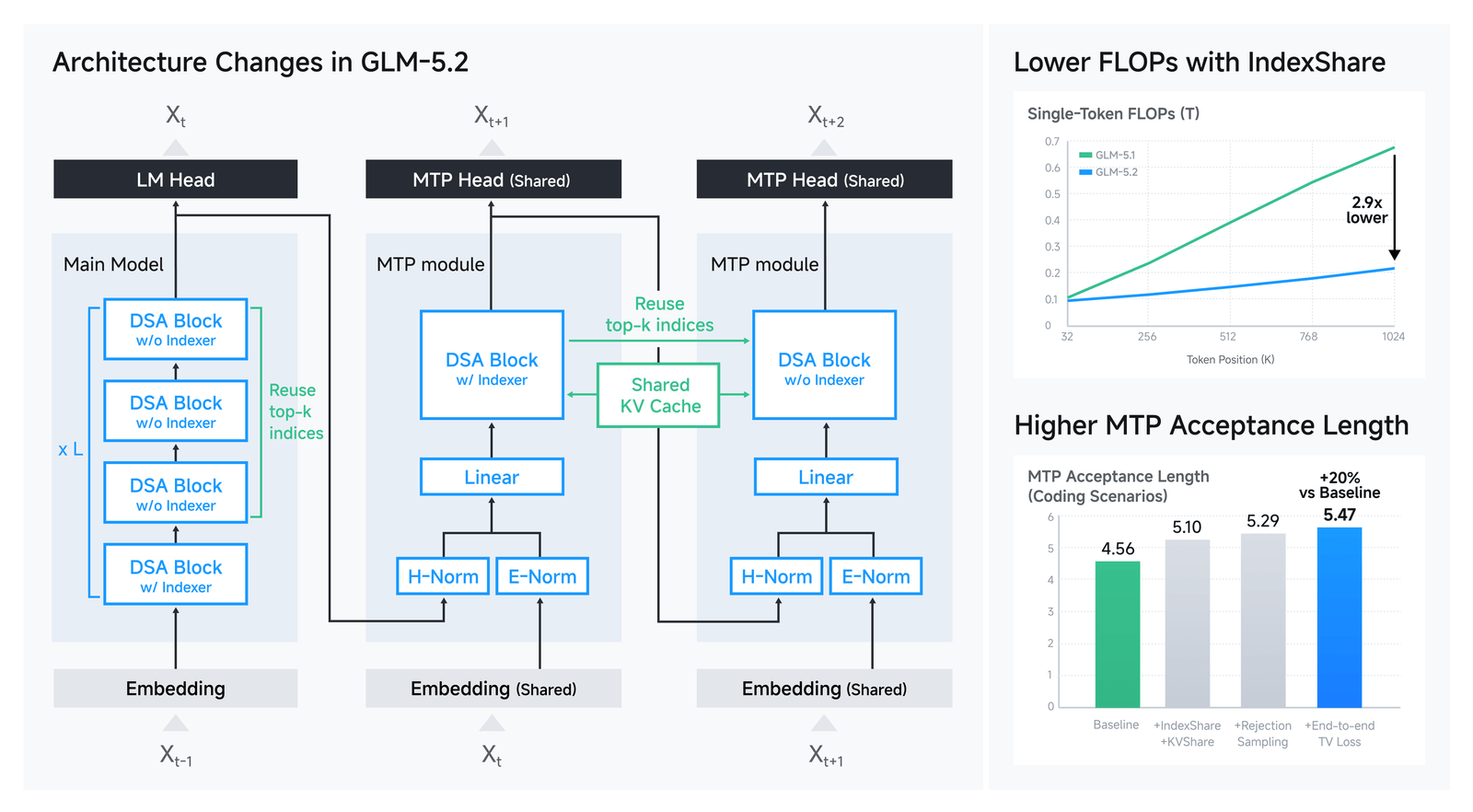
IndexShare: making 1M context cheap
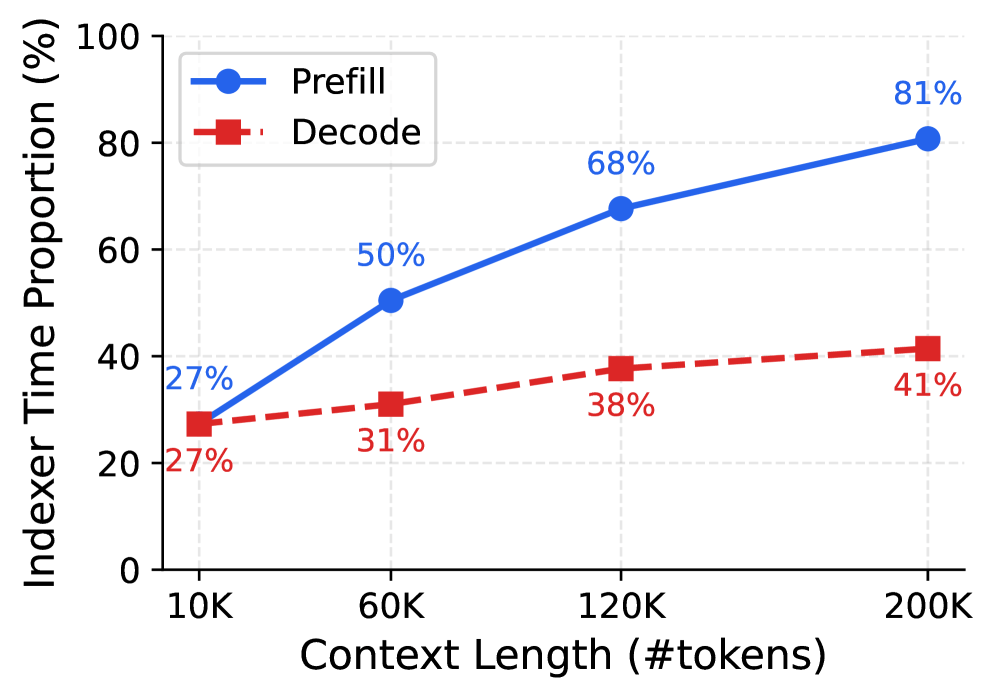
DSA has a catch. The indexer runs at every layer, and as the context grows toward 1M tokens, that per-query top- search becomes the dominant cost. The IndexCache paper's observation is the whole insight: adjacent DSA layers select almost the same tokens — 70–100% of their top- overlap.
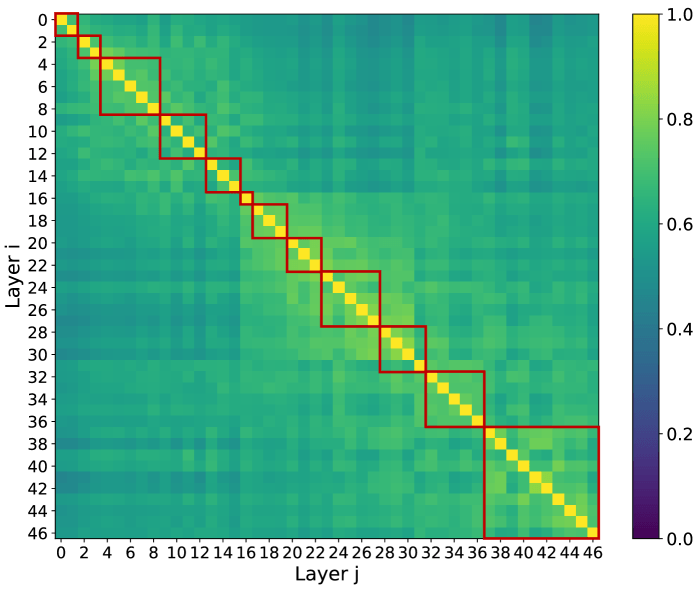
So compute the indexer once per group of layers and reuse its selection for the rest. GLM 5.2 shares one indexer across every 4 layers — skipping it in 3 of every 4:
The indexer runs once per group of 4 layers; the other 3 reuse its token selection. Because adjacent layers pick 70–100% of the same tokens, the reuse is almost lossless — and at a 1M-token context it cuts per-token FLOPs by 2.9×.
If the indexer's cost per layer scales with selecting top- over tokens, then sharing it across a group of layers amortizes that cost to per layer. With and the rest of each layer unchanged, GLM 5.2 reports 2.9× lower per-token FLOPs at a 1M-token context, with quality essentially intact.
The honest tradeoff: push reuse too far — share across 8 layers instead of 4 — and long-context fidelity starts to degrade. One indexer per four layers is the sweet spot the paper settles on.
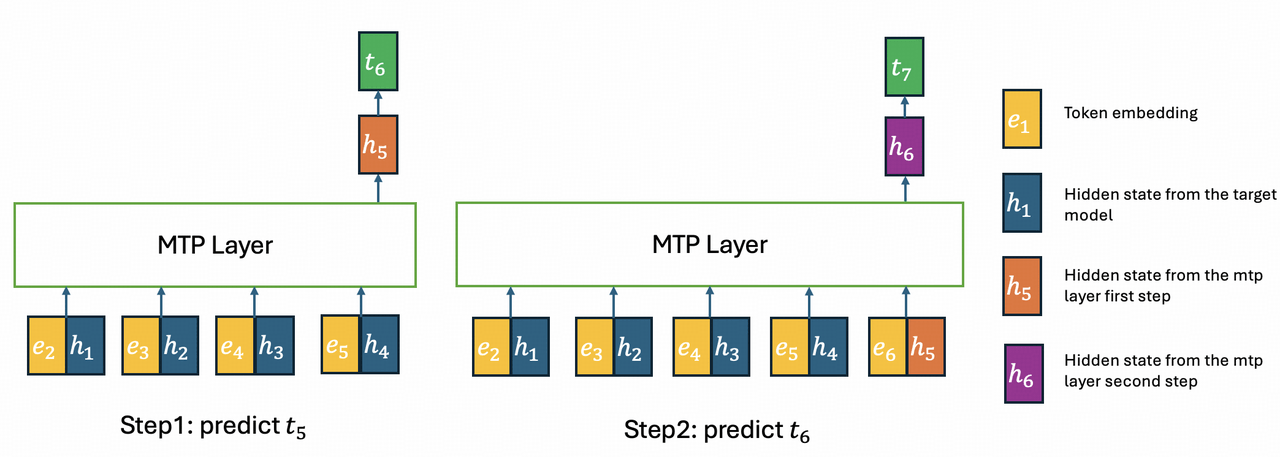
Faster decoding: MTP and KVShare
GLM 5.2 also sharpens its multi-token-prediction layer (speculative decoding). With IndexShare, KVShare, and end-to-end training, the average acceptance length rises ~20% — from 4.56 to 5.47 tokens per verification pass. More accepted tokens per pass means faster generation, which matters most when you are streaming long agent traces.
Training for the long horizon
Pretraining scaled to 28.5T tokens (up from GLM-4.5's 23T). But the interesting change in 5.2 is the agentic post-training. It moves from group-relative RL to a critic-based PPO that estimates token-level advantages from individual rollouts — which accommodates trajectory compaction without capping how long a trace can get. That is exactly what you need when a single agent run is thousands of tool calls long and won't fit in one rollout.
It also adds an anti-reward-hacking module: a rule-based filter first catches likely hacks (tuned for recall), then an LLM judge checks intent; on a detected hack the system blocks the call and returns dummy information so the rollout continues instead of being thrown away. All of it runs on Zhipu's open asynchronous RL framework, slime.
Benchmarks
The headline result: GLM 5.2 is the strongest open-weights model on standard and long-horizon coding, closing much of the gap to Claude Opus 4.8 and GPT-5.5.
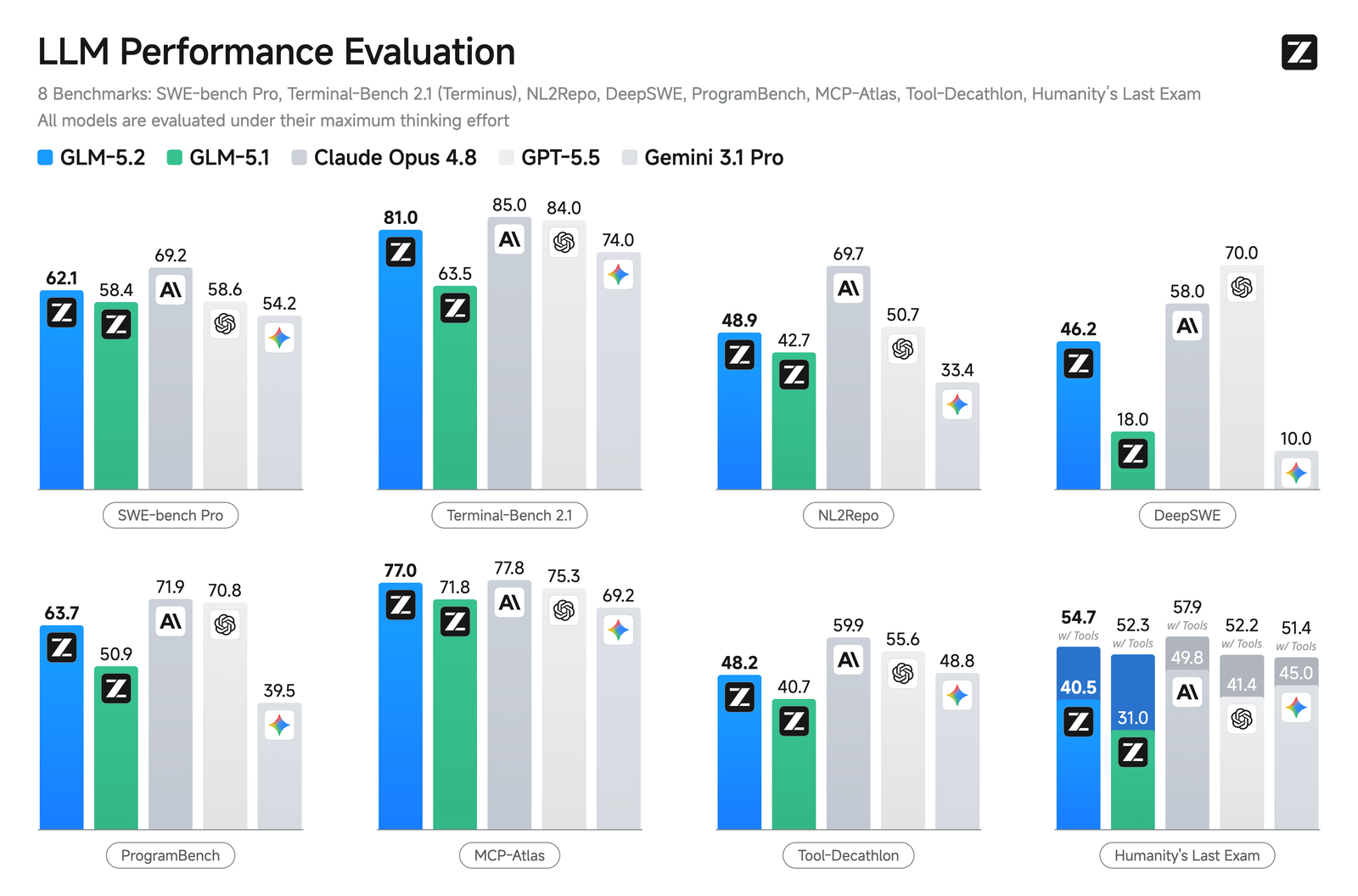
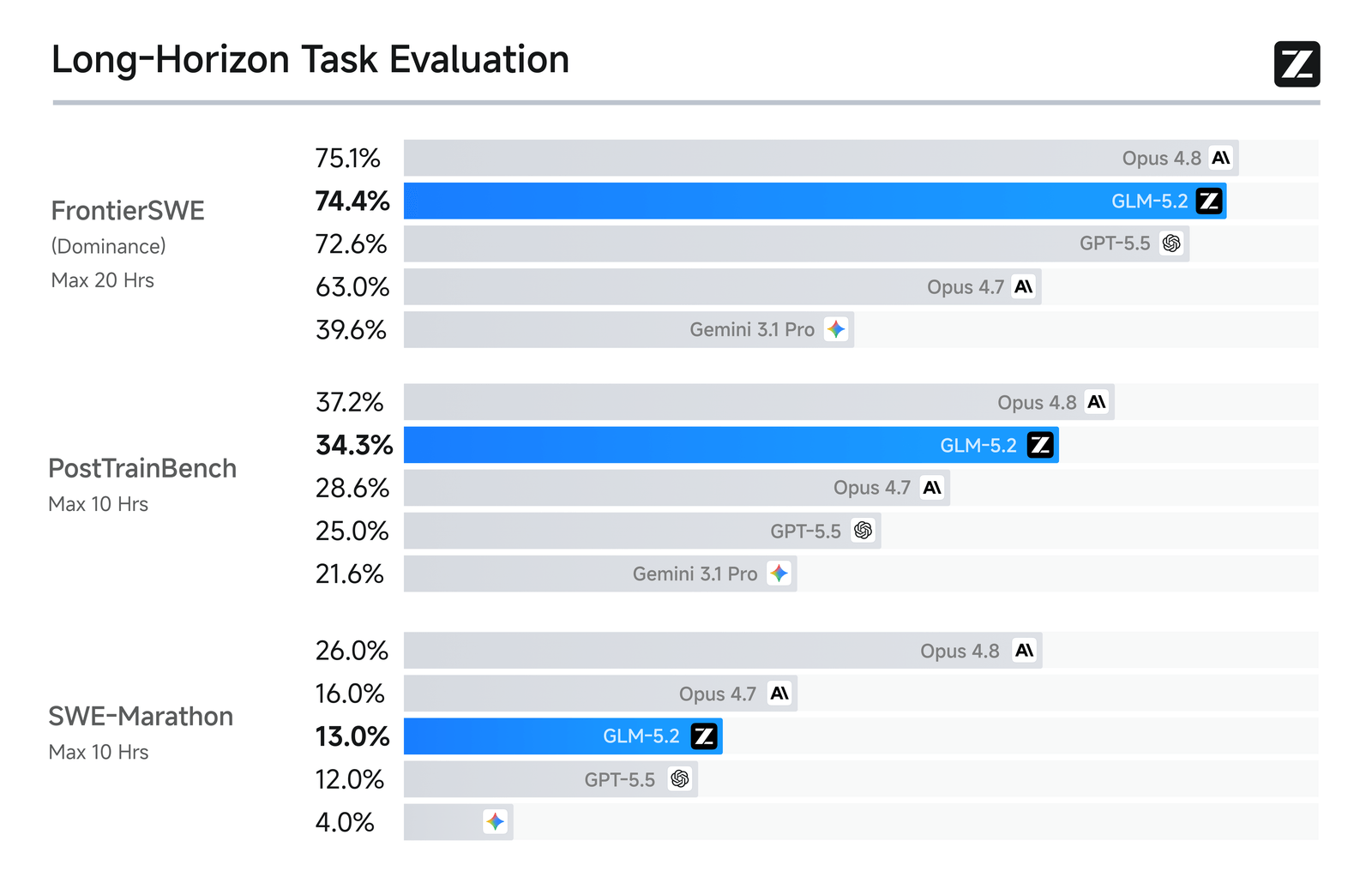
Where it stands out most is long-horizon coding — runs that have to stay coherent over many rounds — where it nearly catches Opus 4.8 and leaves the rest behind:
Reasoning is strong — a near-perfect AIME — though it trails the very top closed models on the hardest knowledge benchmarks (GPQA, HLE):
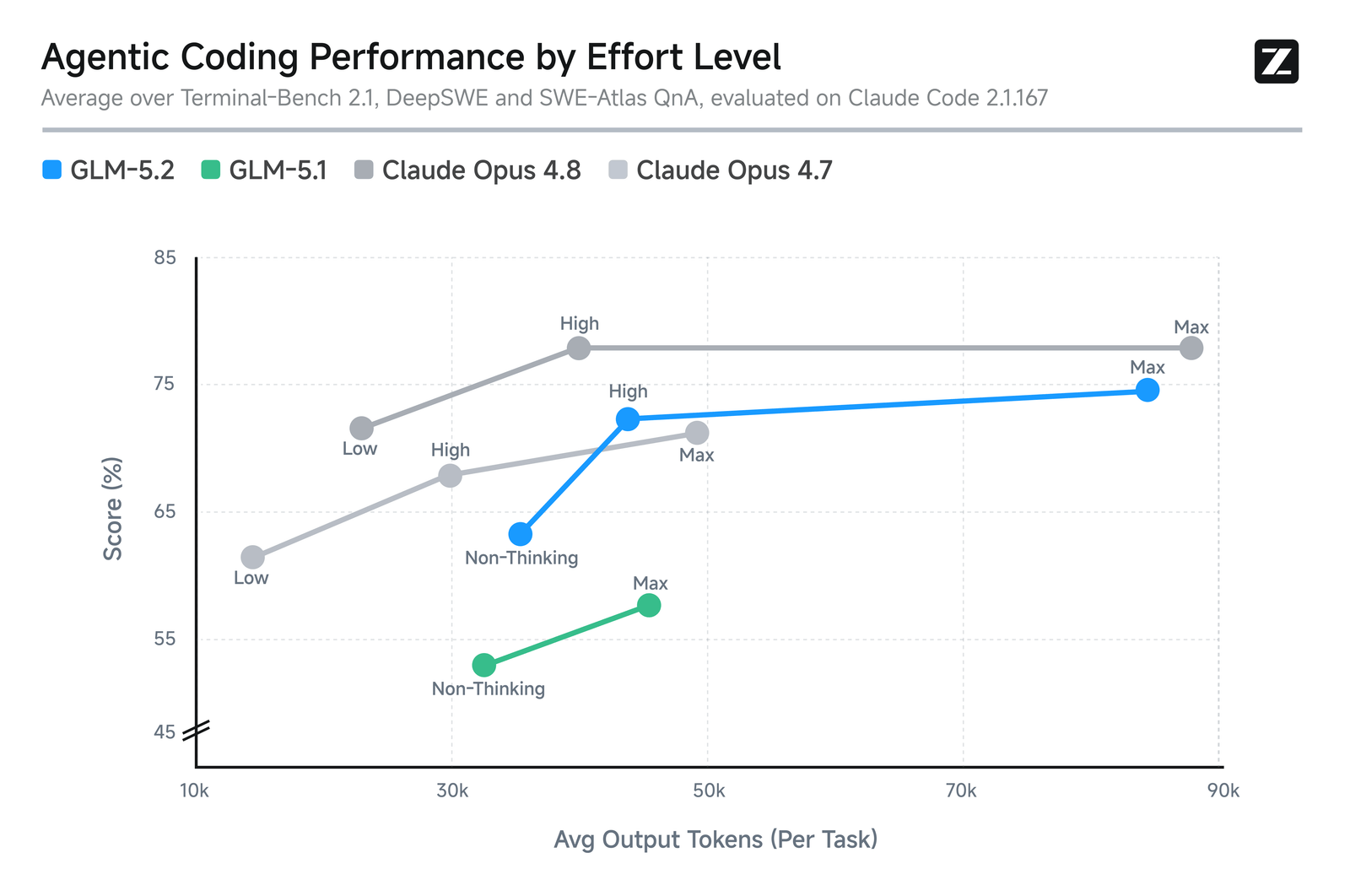
Thinking effort, and what 1M costs to serve
GLM 5.2 exposes two reasoning-effort levels — high for everyday speed and max for
hard multi-step coding — and Z.ai positions its capability between Claude Opus 4.7 and
4.8 at similar token spend.
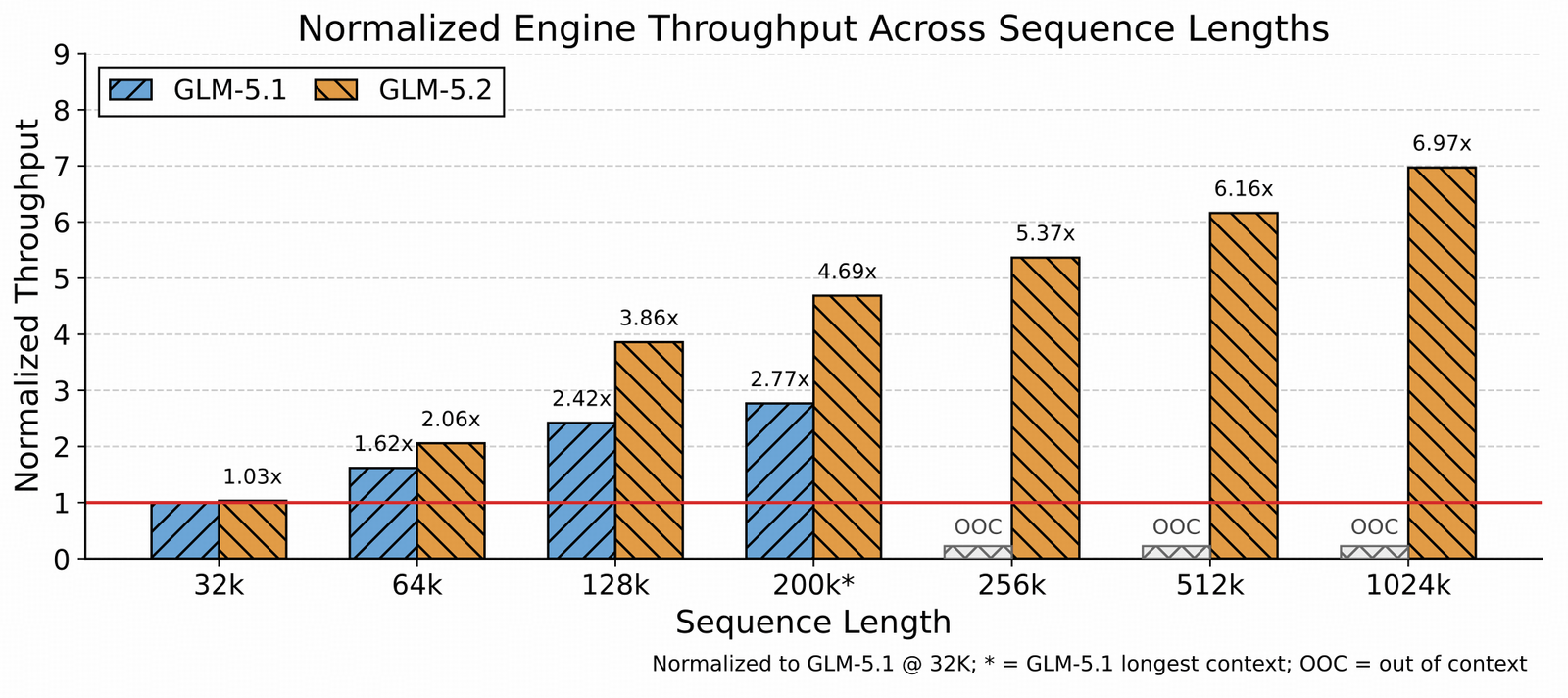
The 1M context is not free to serve. The bottleneck moves from raw compute to KV-cache capacity, long-context kernels, and CPU-side overhead; the throughput advantage grows with context length, but you need 8×H100-class hardware and ~1.5 TB for the weights, and the API meters at 3× during peak hours.
What I make of it
- The genuinely new bit is IndexShare — a clean, well-motivated systems trick (reuse what's nearly identical instead of recomputing it), with a paper that shows why it's almost lossless. That's what turns "1M context" from a spec-sheet number into something you can actually serve.
- It's the strongest open-weights model for long-horizon agentic coding, and it's MIT-licensed. That combination matters more than the benchmark deltas — you can run and fine-tune it yourself.
- It still trails the best closed frontier models on most hard coding and reasoning axes (SWE-Bench Pro 62.1 vs Opus 4.8's 69.2), and it is heavy to self-host. The bet was never "beat Opus 4.8 everywhere" — it's "match the frontier on long-horizon work, in the open, at a million tokens." On that, it largely delivers.
Sources: the GLM 5.2 release blog, the GLM-5 technical report (arXiv 2602.15763), and the IndexCache method paper behind IndexShare (arXiv 2603.12201). Benchmark figures are from Z.ai; numbers quoted as reported.